
Artificial Intelligence And Homer
Looking at the Results of LLM Analyses of the Iliad and Odyssey

This post is a continuation of my substack on the Iliad. Following the completion of book-by-book posts entries will fall into three basic categories: (1) new scholarship about the Iliad; (2) themes: (expressions/reflections/implications of trauma; agency and determinism; performance and reception; diverse audiences); and (3) other issues of texts/transmission/and commentary that occur to me. As a reminder, these posts will remain free, but there is an option to be a financial supporter. All proceeds from the substack are donated to classics adjacent non-profits on a monthly basis.
It can be pretty hard to be in education or research (or online) these days without being forced to think about A(rtificial) I(ntelligence). I often miss earlier years when AI was largely the province of science fiction. I grew up with treacherous space computers (2001), genocidal time-traveling computers (Terminator), and enslaving overlord computers playing around with Platonic caves (The Matrix). When I taught SF and Myth 15 years ago, I placed such narratives under the golem theme with Frankenstein—that anxiety that humankind’s creation would turn out to be our destruction (Hello, Cylon.)

The emerging communis opinio seems to be that AI is here to stay, however we feel about it. And don’t worry, SF geeks, even if it seems rather unimpressive compared to Skynet, there are still some apocalyptic strains: AI may accelerate climate change (and is already causing significant problems, in emissions and water use, out of the sight of most users in the Global North); and, well, AI may radically change employment opportunities throughout the world—eliminating or fundamentally altering up to 60% of jobs in ‘advanced economies’, according to the IMF, and replacing up to 85 million jobs by 2025. So, AI may be apocalyptic, just with more of a whimper than a bang.
Yet AI is not really intelligence at this point—instead, most of what we are talking about with Large Language Models and Natural Language Processing, are predictive and then generative models based on databases produced and provided by humans. They are thinking machines only insofar as they offer up outputs that appear to us to be equivalent to the products of biological thinking machines.
If we can sidestep the environmental and economic impacts of AI—in a way, an act not so different from ignoring the social and environmental horrors of late-stage capitalism writ large—we can begin to think of how to use them as tools. In a way, this takes me back to the early, heady days of DIGITAL HUMANITIES. When it comes to the application of the digital to the humanities, I have basically divided it into two categories: applications that accelerate processes in which humanists were already engaged and applications that create new processes or new forms of knowledge to change the way we look at traditional fields.

Homerists have been ‘text mining’ and using statistics since before the time of computers to try to understand formulaic language, probing questions like the unity of each epic, their ‘authorship’, relative dating, and their chronologies relative to other poems. Indeed, Homerists have been using concordances to examine repetition and variation of Homeric language for nearly 200 years–Guy Prendergast began his concordance in 1847 and completed in in 1963. Before then, scholars relied on their own notes and ‘vibes’--I can only imagine that when Richard Bentley first argued for the impact of the absent digamma on Homeric meter, he was relying on a fairly powerful LLM in his mind. I had the benefit of working with online tools like Perseus (and now the dynamic Scaife Viewer) and the database of the TLG (Thesaurus Linguae Graecae ). These interfaces put students and scholars of ancient Greek in the vanguard of the digital humanities. While most of them qualify as accelerating what scholars had long done with Homer, the interfaces and opportunities themselves altered the way humans engaged with the texts.
But if you look at the mid-late 20th century work of scholars like Hainsworth and Janko on formulaic language in Homer, you can just imagine how the work might have been done differently with more processing power (to say nothing of some of the conclusions). I spent a good deal of time with this work when learning about Homeric language and even more when writing a book on the Homeric Battle of the Frogs and Mice. Camerotto has a fascinating analysis of the parodic language when compared to Homer; Pavese and Boschetti have presented an exhaustive analysis as well. Chiara Bozzone has been doing probably the most cutting edge work on this over the past decade, combining some of the best linguistic frameworks (building on the work of Egbert Bakker and others) with modern statistical and computational models. (She has a new book out, Homer’s Living Language, that I will post about here, as soon as it arrives in my mailbox.)
In the meantime, we do have Bozzone’s work with Ryan Sandell to consider. In their model, they created a database by removing place names and personal names as well as some epithets to create “bigrams” (“sequences of two orthographic words”). Their results show notable differences between the Iliad and the Odyssey; that Iliad 10 seems to be an outlier linguistically, and that some of Odyssean books are closer to the Iliad.

In looking at this chart, I find myself somewhat surprised that the battle books of the Odyssey don’t seem any closer to the Iliad but less shocked about Iliad 9—which is all conversation—plotting near the portion of the Odyssey that is part of Odysseus’ own tale. Some limits of this analysis may reside in their focus on the top 100 word bigrams instead of the whole text. Bozzone and Sandell admit that these results are preliminary, but indicate that the analysis makes a single ‘author’ for both poems unlikely and that both texts are likely to have a “multiple-event” course to textualization.
AI ‘Reading’ Homer
One might imagine we are primed for a new approaches to Homer and Greek poetry using AI (especially LLMs and NLP). I can imagine this working on both predictive and generative axes: an interface that takes manuscript ‘variants’ and evaluates them based on patterns within the entire databases (something humans do already but slowly), models that create emendations to fragments based on similar databases (predictive and generative), even a kind of AI Homeric Centos that creates ‘Homeric’ lines based on our extant corpora.
But we already have scholars using this technology to help reconsider some of our oldest “Homeric Problems”. My friend (and frequent collaborator) Elton Barker introduced me to Maria Konstantinidou who is working with John Pavlopoulos and others using LLMs to analyze Homeric language. In two pieces (from 2021 and 2022/3) they demonstrate the results of their application of statistical language modelling to Homeric texts and its comparison to human interpretation. Their approach analyzes by strings of characters within a framework of perplexity, which is a statistical relationship between what sequence of letters might be predicted in a line based on the total database and the actual sequence in question.
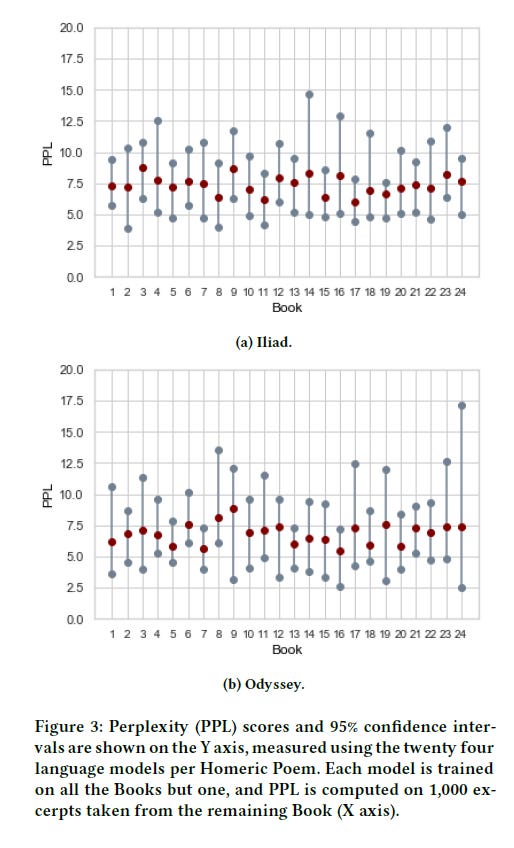
If this seems confusing, that’s ok! I joined Maria in a zoom meeting and she ran through the way the models work for me and we looked at some various lines and talked about some of their questions and plans. Their database includes all of the Allen OCT of the Iliad and the Odyssey with comparisons to the Homeric Hymns and portions of Hesiod. In this first analysis, they find differences between the books of the Iliad and the Odyssey but also some significant divergence across the books of a given epic. Neither of these results surprises me—Homerists have long recognized that different plots and themes generate require different linguistic environments. In comparison to the Homeric Hymns, this model has shown the Hymn to Aphrodite to be ‘closer’ to the Homeric epics while Hermes appears to be farther away from both. In addition, their comparison to human interpretation demonstrates an equivalent level of competence for the computational model.
A significant difference in this approach is the use of characters instead of bigrams. In addition, Maria said they have modeled the data with and without place names and epithets and that the differences are negligible.
The second article builds on this and had me a bit giddy after I finished my conversation with Maria. Here, they recreate ‘heat’ maps from the first article that demonstrate the internal perplexity of given books in the each Homeric epic. The comparisons between the epics show that the Iliad and the Odyssey are each more internally predictive/coherent than they are in relationship to each other (providing support for notions of each epic’s unity). They also show a range of relationships among and between books within each epic. Note: in the chart below, the color shading maps similarities within each epic.

Some takeaways: the work of Pavlopoulos and Konstantinidou provides some pretty convincing support for notions I already held to be true through traditional vibes: the Iliad has more variety in language (internally) than the Odyssey with the exception of books 9-12 of the Odyssey, Odysseus’ narrative. While the epics are drawn from the same larger linguistic database, their internal relationship is stronger than their relationship to each other. This contrast levels out a bit when they are compared to the Homeric Hymns. The battle books of the Iliad (12-17) have more in common with each other than the rest of the poem; and thematic links like politics tie together Iliadic books 1, 9, and 19. Further, their model shows that none of the language within the books sets it apart as non-Iliadic. This means there is no good linguistic reason to consider Iliad 10 as separate from the rest (pro Casey Due and Mary Ebbott; contra M. L. West). In addition, this means their data show that each epic has more in common internally than with the other poem (while there are variations within the books.
Bozzone and Sandell’s analysis does not contradict much of this—I think, with the exception of the differences regarding Iliad 10. Instead, it looks at the way the poems are put together and suggests a gradual model of tetxtualization that confirms, to my mind, the overall arc of Gregory Nagy’s evolutionary model for the development of the epics.
Epilogue and Questions
Given the differences in approach and (admittedly minor) differences in result, there’s clearly more work (and thinking to do). After digesting this data, I sent Maria, John, and Elton a series of questions and ideas to work on:
1. Using the model to trace episodes and composition within books. Maria mentioned the data on the Catalogue of Ships as showing its difference as a compositional unit. What can this model say about different ‘episodes’ within the epic or within a single book? Could we use it to analyze how much the three major sections of book 6 of the Iliad cohere (The first section of warfare; Diomedes and Glaukos; Hektor in Troy) and how they compare in a heat map to the rest of the books of the epic?
2. What can this model tell us about the relationship between the epics and other narrative traditions. A clear example would be a comparison of the catalog of heroines in Odyssey 11 with the fragmentary Hesiodic Catalogue of Women (and for control, comparison to other Hesiodic works
3. Intergeneric comparisons. Hilary Mackie argues that Achilles speaks like Hesiod. Could similar analysis of Achilles' speeches (esp. in book 9) support this? Also, intrageneric comparisons: Do Trojan speakers speak differently from Achaeans? Do gods speak differently from mortals?
4. Plus-verses, variations: What does this model tell us about Homeric multiformity? Can we test evaluate manuscript variants for their perplexity and thereby evaluate editorial decisions (ancient and modern?). What does this model say about assertions of relative dating, e.g. the work of Richard Janko and others?
5. Intergeneric part 2: How difficult would it be to evaluate sections of Homeric language in and against lyric and elegiac corpora? What could this tell us about the relationship of poets like Steisichorus and Sappho with Homeric Language
While I don’t look forward to a future of AI reading scholarship generated by AI about Homer, I am interested in how these applications can help us rethink old questions and re-imagine new ones. If anyone has other articles on this or ideas about collaborations, let me know. I would like to arrange some kind of a virtual workshop in the next year or so.
Short Bibliography
n.b. this is not exhaustive. please let me know if there are other articles to include.
Andersen, Øivind, and Dag T. T. Haug (eds.). 2012. Relative Chronology in Early Greek Epic Poetry. Cambridge: Cambridge University Press
Bakker, E. J. Poetry in Speech: Orality and Homeric Discourse. Ithaca, 1997.
Barnes, H. R. “The Colometric Structure of Homeric Hexameter”. GRBS 27 (1986): 125–150.
Bozzone, Chiara. 2024. Homer’s Living Language. Cambridge.
Bozzone, Chiara and Sandell, Ryan. 2022. “Using Quantitative Authorship Analysis to Study the Homeric Question.” David M. Goldstein, Stephanie W. Jamison, and Brent Vine (eds.). Proceedings of the 32nd Annual UCLA Indo-European Conference. Hamburg: Buske. 21–48.
Camerotto, A. “Analisi formulare della Batrachomyomachia”. Lexis 9-10 (1992) 1-54.
Dué, Casey. 2018. Achilles Unbound: Multiformity and Tradition in the Homeric Epics. Washington, DC: Center for Hellenic Studies.
Edwards, Mark W. “Homeric Style and Oral Poetics”. In Morris and Powell (1997): 261–283.
Fasoi, Maria, Pavlopoulos, John, and Konstantinidou, Maria. 2021. “Computational Authorship of Homeric Language.” DHW: Digital Humanities Workshop 2021: 28-88.
Hainsworth, J. B. The Flexibility of the Homeric Formula. Oxford, 1968.
Janko, Richard. Homer, Hesiod, and the Hymns. Cambridge, 1982.
Janko, Richard. “Πρῶτόν τε καὶ ὕστατον αἰὲν ἀείδειν: Relative Chronology and the Literary History of the Early Greek Epos”. In Andersen and Haug (2012): 20-43.
Nagy, Gregory. 2004. Homer’s Text and Language. Urbana: University of Illinois Press.
Notopoulos , J. A. “ Continuity and Interconnexion in Homeric Oral Composition .” TAPA 82 ( 1951 ): 81–101 .
Parry, Milman. The Making of Homeric Verse: The Collected Papers of Milman Parry. A Parry, ed. Oxford, 1971.
Pavese, Carlo Odo and Boschetti, Federico. A Complete Formular Analysis of the Homeric Poems. Amsterdam: 2003.
Pavlopoulos, J., Konstantinidou, M. Computational authorship analysis of the homeric poems. Int J Digit Humanities 5, 45–64 (2023). https://doi.org/10.1007/s42803-022-00046-7
Ready, Jonathan. 2019. Orality, Textuality, and the Homeric Epics: An Interdisciplinary
Study of Oral Texts, Dictated Texts, and Wild Texts. Oxford: Oxford University Press
Wachter, Rudolf. 2007. Greek Dialects and Epic Poety: Did Homer Have to Be an Ionian?
In Miltiade Hatzopoulos (ed.), Φωνῆς χαρακτήρ ἐθνικός: Actes du Ve congrès internationale
de dialectologie greque, 317–28. Paris: Boccard.
West, M.L. 2001. Studies in the Text and Transmission of the Iliad. Munich: De Gruyter.
West, M. L. “Towards a Chronology of Early Greek Epic”. In Andersen and Haug (2012): 224–241.
A helpful addition from Stephen Sansom:
Though not on Homer (yet), Graziosi et al. (TAPA 2023 ) use the deep learning model BERT to evaluate likelihoods of variants and emendations (and have a great bit on contextualizing philology in this light at the beginning): https://muse.jhu.edu/article/901022.
Also Assael et al. (Nature 2022) on emending inscriptions with a deep neural net (aptly named "Ithaca") seems primed for application to epic fragments (Ehoie especially): https://www.nature.com/articles/s41586-022-04448-z.
Though not on Homer (yet), Graziosi et al. (TAPA 2023 ) use the deep learning model BERT to evaluate likelihoods of variants and emendations (and have a great bit on contextualizing philology in this light at the beginning): https://muse.jhu.edu/article/901022.
Also Assael et al. (Nature 2022) on emending inscriptions with a deep neural net (aptly named "Ithaca") seems primed for application to epic fragments (Ehoie especially): https://www.nature.com/articles/s41586-022-04448-z.