

Last week we held our (first?) Homer and Artificial Intelligence Workshop and it was fascinating. The conversations provided new directions, new questions, and some new ways for thinking about applying modern technology to ancient epic. I recorded and posted the video on youtube (with one section removed to protect unpublished material). Below are some notes as well.
A Quick Primer on Modern Computing: Statistics, LLMs, and AI (20-25 minutes)
John Pavlopoulos
JP gave an overview of how to use relative frequencies of n-grams, basic probability, and language models in Python and demonstrated how he trained a model on the first book of the Iliad to generate pseudo-Greek.
He then showed a model based on perplexity (the distance from expected outcomes of strings of letters based on the models included) and answered questions about misconceptions about statistical models. JP suggested that a signal problem is “If you torture the data enough, it will produce results.”
Research Presentation: Maria Konstantidou, John Pavlopoulos, Elton Barker
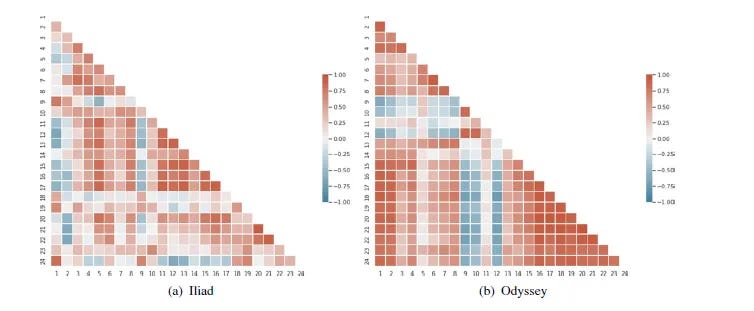
MK, JP, and EB presented some of their work using perplexity based statistical models to consider the Iliad, Odyssey and their traditions. They have created correlation maps of each epic and compared them
Some of their results show that Iliad 10 and Odyssey 24 are not outliers and that there are important statistical correlations across books that also have thematic affinities
Pavlopoulos, J., Konstantinidou, M. Computational authorship analysis of the homeric poems. Int J Digit Humanities 5, 45–64 (2023). https://doi.org/10.1007/s42803-022-00046-7.
Response and Questions: Stephen Sansom, FSU
In his response, SS talked about how to define the relationship between some of the statistical models and what we call Homer. He asked pressing questions about the methodology and the ‘tokens’ that correlate to the differences in Odyssey 9-12. He also talked about the importance of statistical models to Homeric studies historically and pragmatically
From Sansom:
https://grbs.library.duke.edu/index.php/grbs/article/view/17015
https://muse.jhu.edu/article/819768/summary
Research Presentation: Chiara Bozzone, Ryan Sandell, LMU München
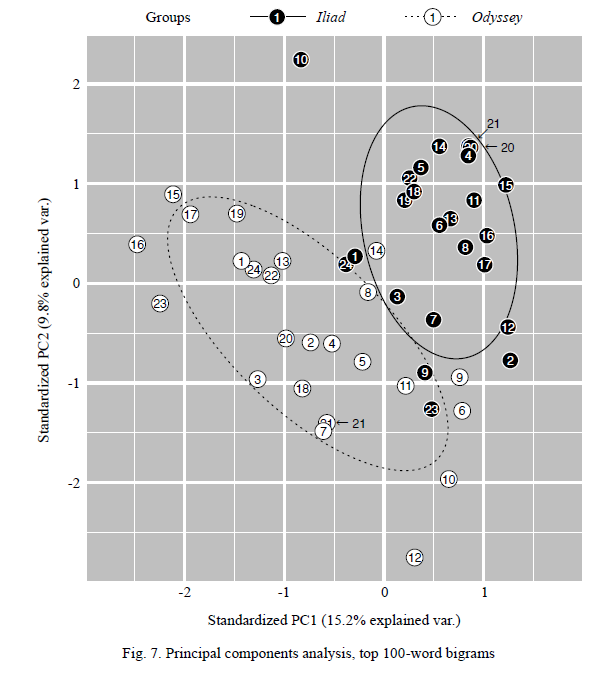
CB and RS presented some results of their work based on authorship attribution models to examine the Iliad and the Odyssey. This approach shows that no clear stylistic node dominates all of both epics and the evidence indicates two poems from similar traditions (but separate ‘authors’) subject to later additions.
Response and Questions: Justin Arft, UT Knoxville
JA’s response asked questions about the correlation heatmaps from the work of JP, MK, and EB, and how different results might issue from training on bigrams or different characters. He focused on some concrete examples to help to illustrate how the selection of passages and selection of detail may alter the results
Bozzone, Chiara. “HoLM: Analyzing the Linguistic Unexpectedness in Homeric Poetry.” With John Pavlopoulos, Ryan Sandell, and Maria Konstantinidou. LREC-COLING 2024, 8166–8172. https://aclanthology.org/2024.lrec-main.715.pdf
Bozzone, Chiara. “One or Many Homers? Using Quantitative Authorship Analysis to Study the Homeric Question.” With Ryan Sandell. In David M. Goldstein, Stephanie W. Jamison, and Brent Vine (eds.). Proceedings of the 32nd Annual UCLA Indo-European Conference. Hamburg: Buske.
Computational Research Labs in Classics Departments: Lab-Based Frameworks for Scholarship and Funding (10-15 minutes) Annie K. Lamar, UCSB
AKL presented some of her efforts to train students on computational research and set these in relief to the structural challenges of doing so in higher ed. For more information, see the Lorel Lab homepage
Response and Questions: Suzanne Lye, UNC Chapel Hill (10-15 minutes)
SL discussed a Classics Lab at UNC and the importance of cross training within a hybrid humanities model. She emphasized the need for institutional support for interdisciplinary research and training.
Research Presentation: Some Homeric Challenges to Machine Learning, Barbara Graziosi, Johannes Haubold, Jacob Murel, Princeton University (10-15 minutes)
JH and JM presented on overview of the Logion project at Princeton, a project that aims ”to develop an NLP tool that aids the restoration and elucidation of premodern Greek text”. They provided a demonstration of how they have used the text with authors like Michael Psellus and how they plan to use it in the future. It uses a large database to provide likely completions to incomplete manuscripts but needs a human philologist to judge the merit and accuracy. We discussed additional challenges for developing Logion for metrical texts and the challenges of considering homogenization through editorial processes over time.
A work in progress talk, “Machine Learning and the Text of Aristotle”
Was a fantastic webinar! I felt spoiled that two of my interests converged in one session, Homeric Studies and cutting edge machine learning, that doesn't happen very often! Thanks Joel for organizing!!